Learning by Distillation: A Self-Supervised Learning Framework for Optical Flow Estimation
发表机构与时间 : TPAMI 2021
第一作者:Pengpeng Liu
论文地址 :戳这里
源码地址 :无
泛读
导言:
问题: 一是如何在不依靠大规模合成数据的条件下,仅仅依靠无标签真实数据来进行有监督光流估计的预训练;二是如何利用无标签数据学习带有遮挡挑战的光流估计任务
难点:
相关工作:光流领域
本文工作:
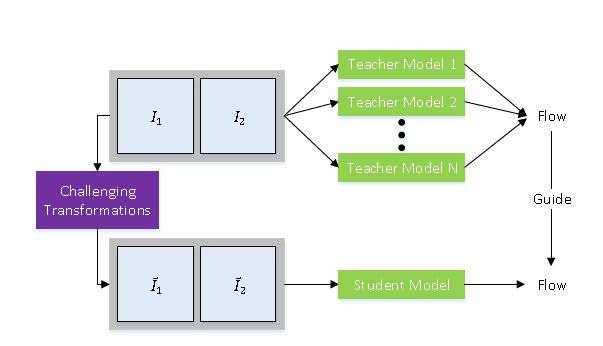
本文提出利用蒸馏的方法来进行自监督光流估计的学习。其一是两阶段的模型蒸馏,第一个阶段利用多个教师网络进行自监督学习,通过模型集成挑选出教师网络中置信度较高的光流估计结果,以此作为下一阶段对学生网络的标签。这解决了第一个问题,为有监督光流估计提供了更好的预训练学习范式。其二是数据蒸馏,即人工对输入数据创造具有挑战性的变换,包括遮挡变换、几何变换和色彩变换,从数据层面驱动模型学习处理遮挡场景的光流估计能力,从而解决了第二个问题。本文除了在KITTI数据集上取得了SOTA的性能外,还具有来良好的泛化性能,这包括适用于多种网络结构,泛化到立体匹配问题上,以及跨数据集的泛化性能。[1]
阅读过程的疑问和感悟
如何保证老师模型输出的光流精度很高?不高的话又怎么指导学生模型?
这个在sintel中表现不如RAFT,但是在KITTI达到了SOTA
在此之前不知道“知识蒸馏”,以后拜读一下Hinton的:Distilling the Knowledge in a Neural Network
特色:
具有良好的泛化性能
精读
原理:
实验:
代码:
参考文献
[1] paperweekly
[2] 引用文章标题2
[3] 引用文章标题3

